




Microservices Unleashed: A Comedy of Code and Infra
Welcome to Microservices: The Tiny Titans of infinite Tech! Here the tiniest pieces make the mightiest impact, and every service is a superhero with its own ego and might!
In this pulsating world of software development, we’re going to embark on an electrifying journey through the microverse. It’s a universe teeming with independent, autonomous services, each one as unique and powerful as a quark, working together in unison to build the next generation of applications!
In an evil galactic empire of Monoliths there stood a sprawling metropolis “Monolithopolis” of tightly coupled code, where functions held hands and databases clients backbiting their masters.
One day, a wise rebel architect named Bob had an epiphany. “Fellow developers, behold! We shall break free from the shackles of Monolithopolis! Introducing… Microservices!”
The crowd shrugged “What are these microservices?”
Bob smiled and explained a future where each service would be a quirky neighborhood; We’d have ‘Userville’ for authentication, ‘Productburg’ for catalog management, and ‘Payment Heights’ for financial transactions.”
“And how do they communicate?” someone asked sarcastically.
They will use APIs—the magical Hermes of the digital realm. Imagine how faster than Flash he will be flitting between services, delivering messages like ‘Hey, Userville, can you validate this token?’ or ‘Productburg, update your inventory!'”
The crowd started taking interest and nodded in agreement, impressed.
“And what about scaling?” a grumpy Sysadmin inquired.
Scaling is our fortress when Userville gets crowded, we clone it like Sonny from iRobot. And when Payment Heights needs more horsepower, we wave our magic wand and breathe life into new instances.
This is chaos, madness, we will be doomed !! exclaimed a worried QA engineer.
Bob angrily, we’ve got chaos monkeys, mischievous creatures that randomly crash services. It’s like a game of musical chairs that keeps us on our toes!
Bob raised a cheer “To agility, independence, and loosely coupled components! May our services thrive, our APIs never 404, and our logs be as entertaining as Shakespearean dramas.
Finally, the bored engineers made Microservicesville flourish. The streets buzzed with RESTful chatter, and the microservices frolicked to the rhythm of asynchronous events. Occasionally, a few services would go rogue but with uncle Bob’s stick they would gently be reminded that “No service is an island.”
Design Patterns
Similar to Gangs of Four (GoF) Design Patterns, certain recurring themes can be identified in Microservices as well, let’s see if we can leverage some of them in our implementation,
Dedicated Database for Each Service
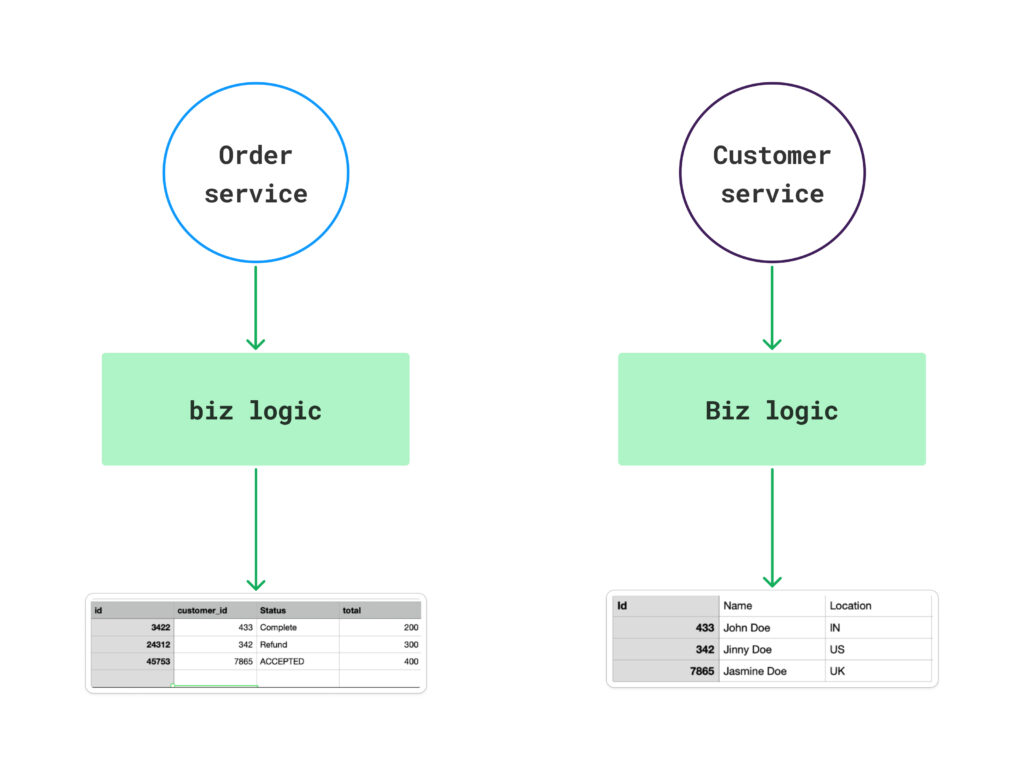
A database dedicated to one service should not be accessed by other services. This makes schema or table alteration simple and easy without the risk of the entire application going down, this is one of the reasons that makes it much easier to scale individual services.
Imagine a situation where the demands or access requirements of your databases vary. One service may own most of the relational data, while a second service would benefit more from a NoSQL solution and a third service might need a graph database. You could find it easier to handle each database in this case if you use dedicated services for it.
A single shared database isn’t the standard for microservices architecture but isn’t a taboo either, sometimes it is enforced due to Org restriction as well as monetary considerations. We can enforce logical boundaries if such a case arises for e.g. each service should have its own schema, and each service has its own creds with restricted access so that CRUD can only happen to schema/tables which are owned by that service.
SAGA
Some business transactions span multiple service so you need a mechanism to implement transactions that span services for e.g. Orders and Customers are in different databases owned by different services the application cannot simply use a local ACID transaction.
A saga is a sequence of local transactions, each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails then saga executes a series of rollback/compensating transactions that undo the changes that were made by the preceding local transactions.
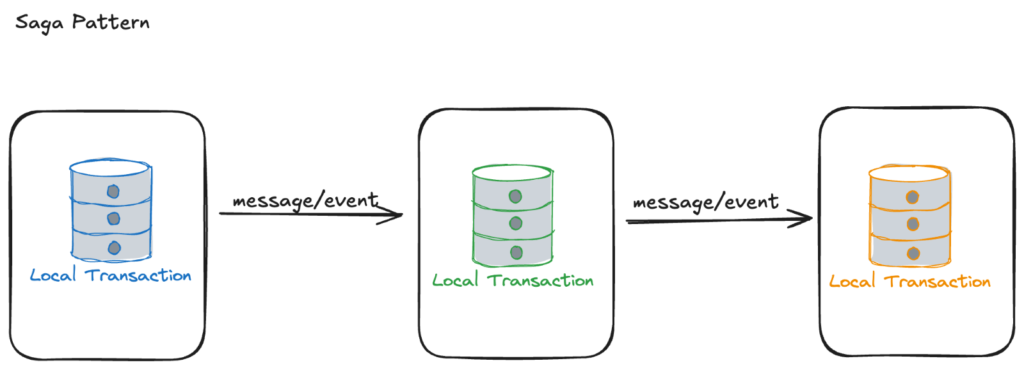
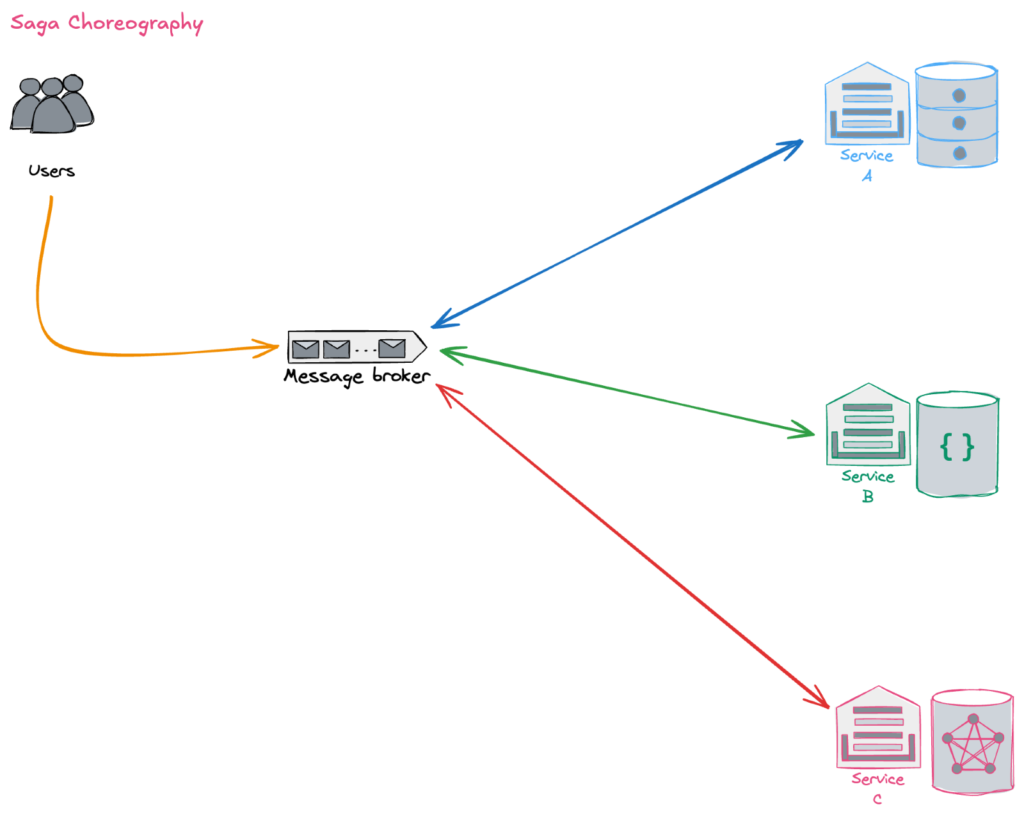
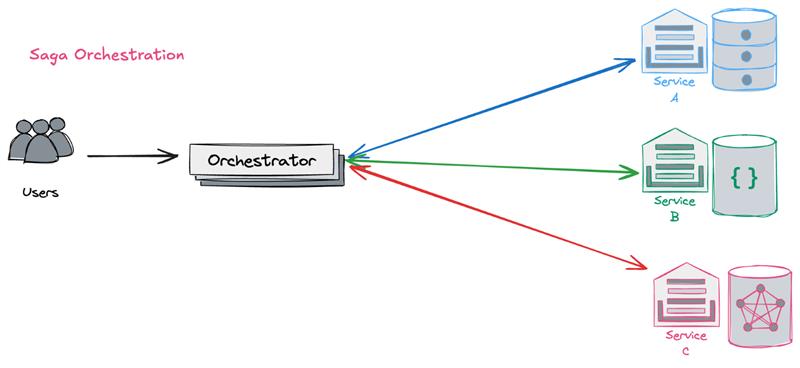
There are two ways of coordination in Saga,
- Choreography – each local transaction publishes domain events that trigger local transactions in other services.
- Orchestration – an orchestrator (object) tells the participants what local transactions to execute.
Command-side replica
As no Service is an island, they often needs to query other services for updated information, for e.g. in a food ordering system the ordering-service might need to often check with restaurant-service for available dishes and prices for eventual ordering. This results in a lot of chit-chattering between services, some optimizations can be performed like async calls and caching but they are partial remedies still degrading the User experience.
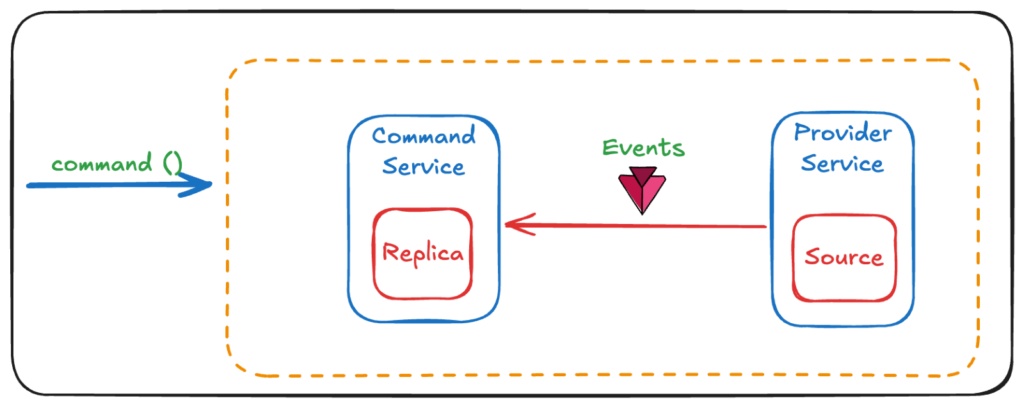
An alternate approach to this may be from the realms of NoSQL (data redundancy, as space is no longer a constraint) to replicate the restaurant menu and prices as a read-only data at ordering-service.
In this approach, a command-service replicates the data from provider service (that owns the data) to replica database, it is the job of command-service to keep the data up-to-date by subscribing to the events published by provider-service.
Access token
We have an API gateway as the single entry point for all client requests, it authenticates the requests and forwards it to the respective service which may in turn forward or invoke other services; all these services may need to know the User for checking authorization and hence the identity of the requestor needs to be known and verified.
Here, API gateway authenticates a request and creates a new access token that securely identifies the requestor for further invocations. Services can propagate this token to other invoked services.
Distributed tracing and Exception tracking
Requests are often spread across multiple services in microservices architecture, each service handles its tasks by performing db queries, executing business logic etc. here poses a problem of identifying individual behaviors of a service, external monitoring mostly tell the User friendly error but developer troubleshooting goes for a toss, again the logs may be scattered across multiple file entries and that too will be difficult to identify given the hundreds of invocations. We need a solution that has minimal overhead and help us find the rouge service fast.
A few simple steps can mitigate these challenges.
- Assign each request a unique id
- pass the same id to all the services involved in fulfilling the request
- include this id in all log messages, warn, info or error
- create a centralized exception and logging service (e.g. logstash or FluentD) that aggregates all logs in a central place
Health Check API
Sometimes the services become unresponsive due to exhaustion of resources, they may be running and guzzling CPU but may be incapacitated to fulfill the request e.g. it might have exhausted DB connection pool or ran out of storage space allocated to it. This should result in Load balancers to stop routing request to the affected instance and the service registry may opt to pause the discovery of this failing instance.
To detect that a running service instance is unable to handle requests, a service should implement a health check API endpoint (e.g. HTTP /health) that returns the health of the service, this endpoint should return the current health status of the service by
- Status of connections to DB or Queues or any frequently used external component.
- Status of the host machine like disk space or RAM usage.
- A simple application related read-only idempotent operation/logic like fetching a test User or transaction.
Hope these patterns help in the seamless implementation of Microservices.
That’s all folks !!
Please let us know your feedback on this block at [email protected]