




Mastering Database Partitioning: Techniques and Best Practices.
Humans have exceptional organizational skills, probably that’s one of the reasons for the success of us as a species; we have always been organizing and maintaining objects to make it easier to find and maintain, notice how Mom’s have traditionally organized our kitchens to keep the most used spices at an easier location while asking you/Dad to pull some of the lesser used items from the top shelf.
Since the human brain is so good at copy pasting, this concept got applied to Databases as well; Partitioning is dividing the tables and indexes into smaller and smaller pieces that make logical sense. (see how library organizes Newspapers by date and years).
Database partitioning, sometimes known as data partitioning, is a technique used to split a large database into smaller chunks called partitions. Each partition contains a subset of data and is stored and accessed separately. It may even be a key requirement for large databases needing high performance and high availability.
Partitions allow tables and indexes to be subdivided into smaller pieces, enabling these database objects to be managed and accessed at a finer level of granularity. Some benefits of partitioning are
↑ Increases performance by only working on the data that is relevant (recall the spices logic in kitchen).
↑ Improves availability through individual partition manageability {again things that are more frequently accessed gets prime real estate (memory and space allocation)}.
↓ Decreases costs by storing data in the most appropriate manner.
↓ Decreases downtime, if designed correctly the downtime at one instance will not have an impact on other partitions, backup and recovery can also be executed per partition independently from other, hence reducing any downtime.
It is easy to implement as it requires no changes to applications and queries.
Mature Feature – supports a wide array of partitioning methods
Note: Indexes are exceptional and indispensable for database performance, and they work great on partitions, indexes will give Nitro boost to the queries over the partitions.
Here are some common types of data partitioning techniques:
- Range,
- List,
- Hash,
- Horizontal,
- Vertical,
- Key-based,
- Round-robin
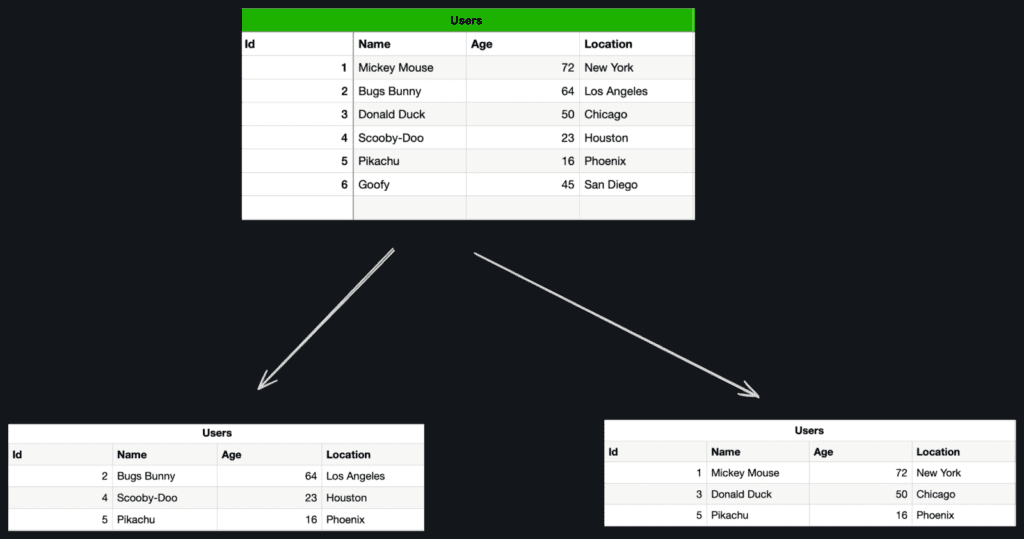
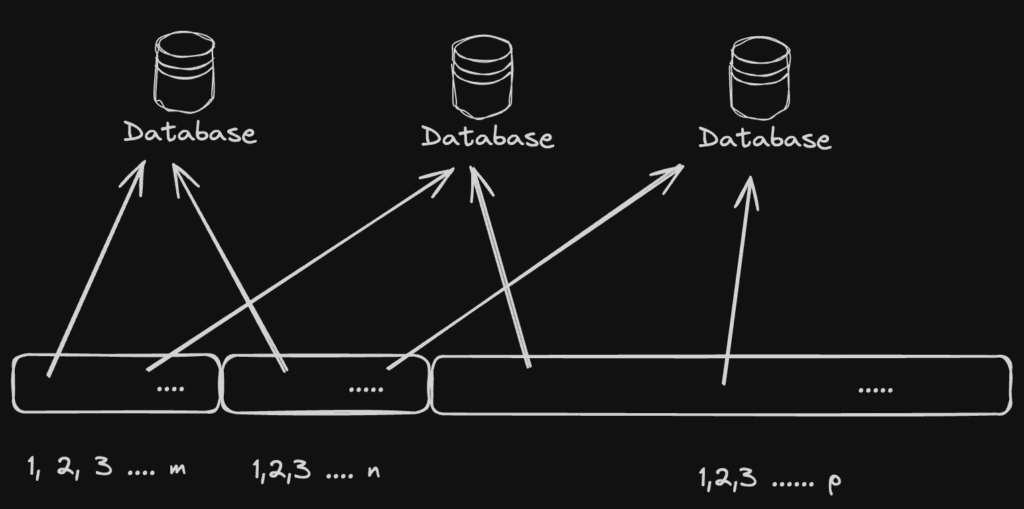
1. Horizontal Partitioning: In this technique, the dataset is divided based on rows or records, each partition contains a subset of rows with a common attribute or value and is typically distributed across multiple servers or storage devices.
Range, List, Hash and composite are different strategies for horizontal partitioning.
For e.g. in the below example the User data can be partitioned based on id-range or location based on geographic areas.
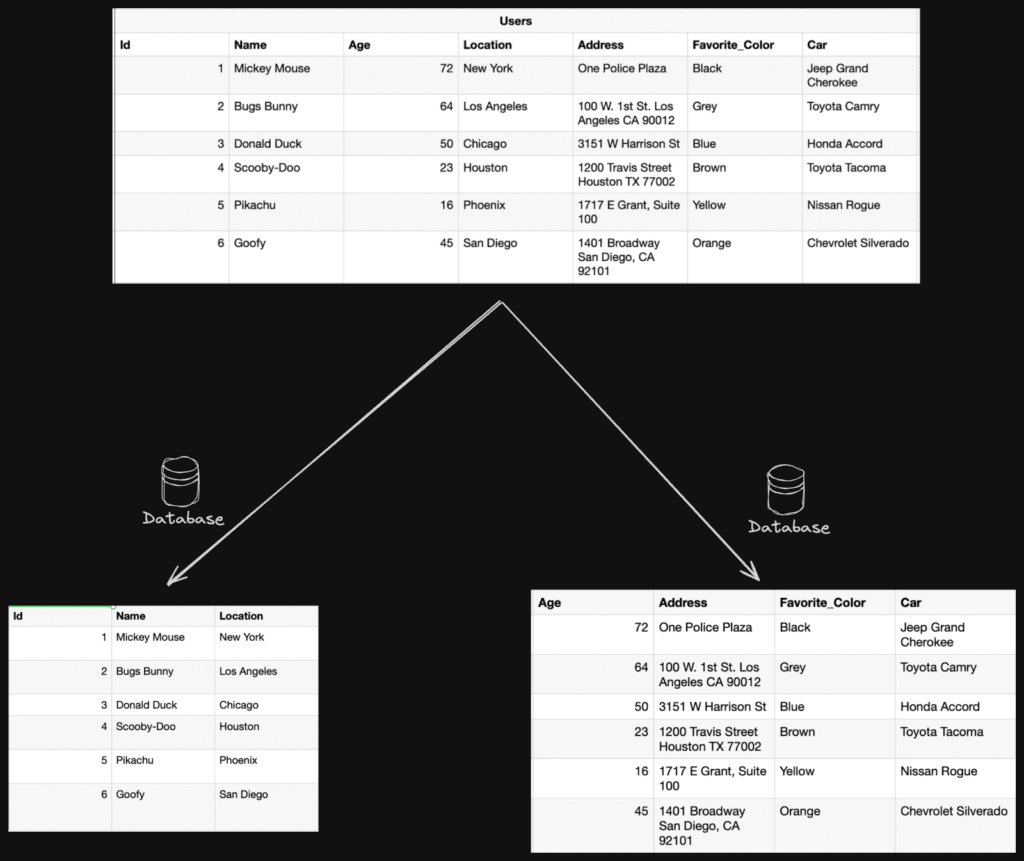
2. Vertical Partitioning: In this approach the dataset is divided based on columns or attributes, each partition contains a subset of columns for each row/record.
It is used to optimize storage and improve performance by grouping related columns or the ones retrieved simultaneously together. A common use-case of vertical partitioning is to separate static, slow-moving data from the ones that are used more frequently.
3. Key based: In this approach the dataset is divided on an attribute value. If correct keys are chosen (preferably natural keys which occur uniformly or are evenly accessed), Key-based partition distribute data uniformly across partitions providing better parallelism and improved scalability; an uneven distribution can lead to data skew and hotspots defeating the entire purpose of partitions.
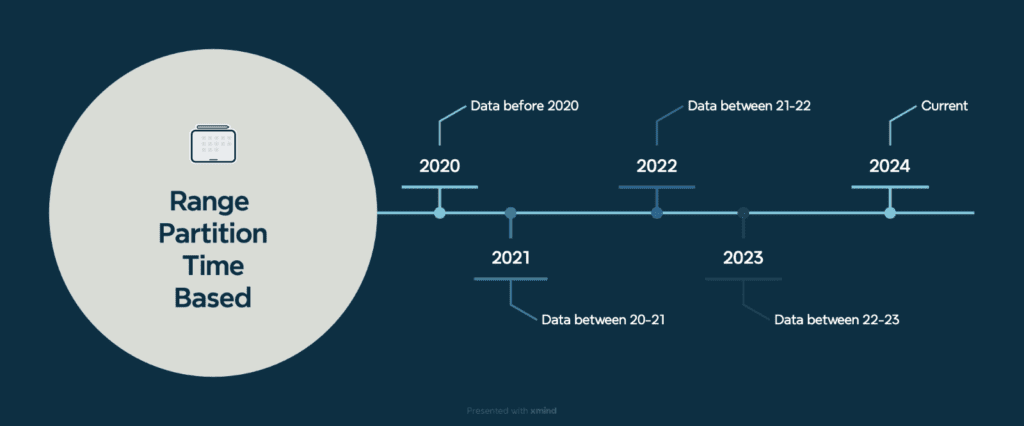
4. Range: In Range partitioning the dataset is divided according to a predetermined range of values. We can divide data based on a particular time range, for instance, if your dataset contains timestamps. When you want to distribute data evenly based on the range of values and have data with natural ordering.
There are several advantages to Range based partitioning, like Natural ordering (time or id based) resulting in even-data distribution, moreover this data can be archived easily once it has passed its active usage life. Also, the queries can be optimised based on these ranges.
5. List : Datasets are divided into partitions based on specific values or a list of discrete values. Each partition is assigned a list of values, and any data items matching those values are stored in the corresponding partition.
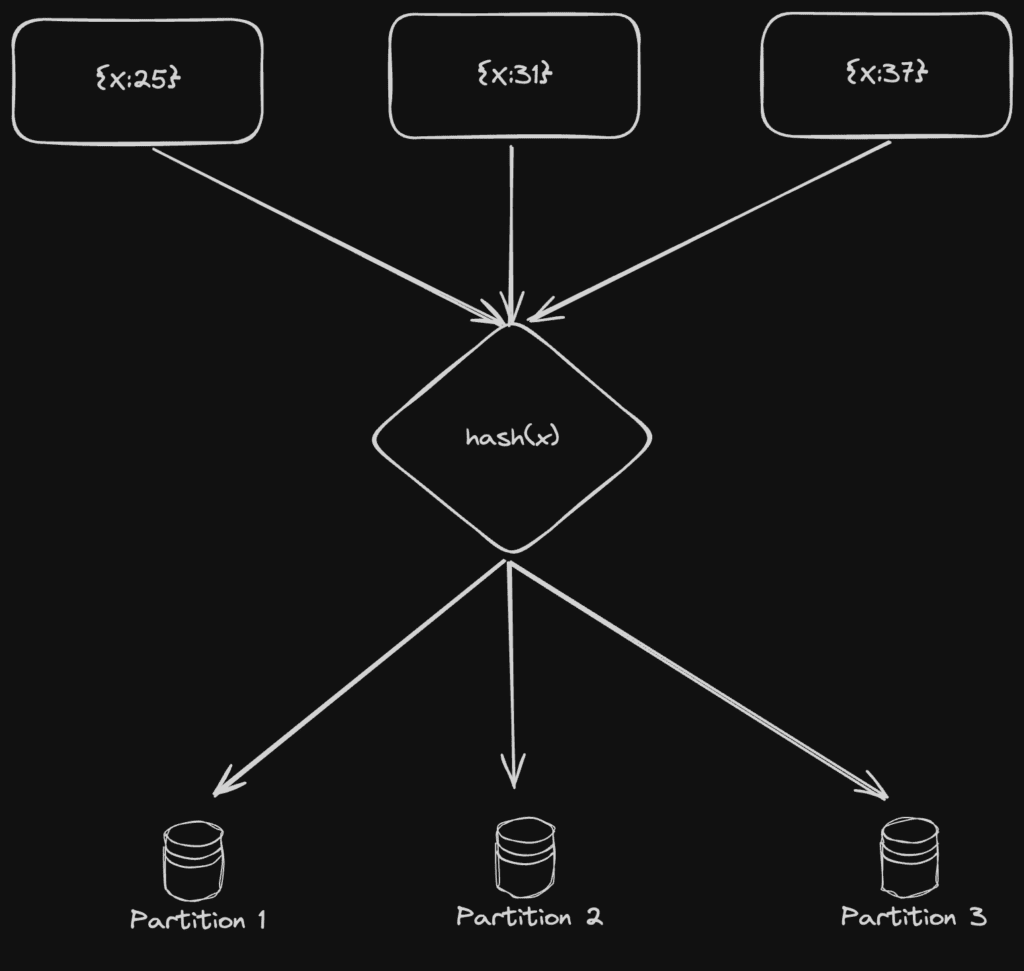
6. Hash : Hash partitioning distributes data based on a hash function applied to a key attribute, this function generates a hash value for each data item, and the item is assigned to a partition based on calculated value.
It provides a random distribution of data across partitions, ensuring even data distribution and load balancing. Hash-based partitioning enables scalable parallel processing by evenly distributing data across multiple nodes.
7. Round-Robin : Round-robin sharding evenly distributes data items across partitions cyclically. Each data item is assigned to the next available partition in sequence. It is simple and straightforward to implement, as it assigns data items to partitions in a cyclic manner without relying on any specific data characteristics.
As it does not consider any data characteristics or access patterns, which may result in inefficient data retrieval for certain queries and suboptimal query performance. Another problem occurs when uneven data distribution or partitions not a multiple of the total number of data items may cause round-robin partitioning to produce unequal partition sizes.
Best practices for Data Partitioning
Here are some steps to design and implement a data partitioning strategy that maximizes performance, scalability, and manageability while efficiently handling the data workload.
Understand data and its characteristics: Understand the data, its structure, access patterns, and relationships. Analyze how the data is distributed, its size, and growth patterns (like mostly static or transactional or metadata) to make informed decisions.
Identify Partitioning criteria: Identify the appropriate partitioning attributes and key(s) to distribute data evenly, minimize data skewness, and optimize for common query patterns filters or join conditions.
Scalability: Ensure that the partitioning strategy allows for easy addition or removal of partitions as the dataset grows or workloads increase.
Balanced Data Distribution: Always aim for even data distribution across partitions to prevent hotspots and ensure optimal utilization of system resources.
Optimize performance: Analyze the data access and common query patterns, optimize the partitioning strategy to align with those patterns.
Monitoring and Maintenance: Implement monitoring mechanisms to track the health and performance of the partitions. Regularly analyze data distribution, performance, and resource utilization to identify locks, imbalances or bottlenecks.
Partitioning changes: With the growing business the possibility of changing partitioning requirements cannot be ruled out. We should construct a flexible system design that allows easy modifications to the partitioning strategy.
Hope you find this article well and understand how to manage the data that gives optimal performance at scale.
That’s all folks!!