Recursive invocation with Amazon S3 and AWS Lambda
Recursive invocation is when one service is sending event to second service and output of second service is the input of first, serverless applications are often composed of services sending events to each other for processing and sometimes they miss the exit criteria for concluding the sequence of events, similar scenario occurs when we have a new object pushed to S3 and that object needs to be processed and put back to S3 (sometimes in the same folder space)
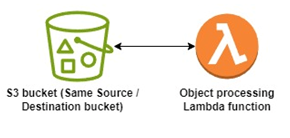
Developers often miss noticing the minute details of their implementation leading to infinite loop (unfortunately this get recognised a bit late as millions of recursive lambda invocation doesn’t fail the server immediately causing out-of-memory error but the massive scaling available with cloud infrastructure allows processing of millions of invocation to only show logs or billing), this will cause a huge setback in billing as S3 & Lambda starts charging for all the data processing and invocations happening.
To avoid recursive invocations between S3 and Lambda, developers should be careful and must take different source and destination buckets, the destination if not possible to be entirely separate can be a subfolder inside the source folder with ‘processed’ tags or prefix/suffixes.
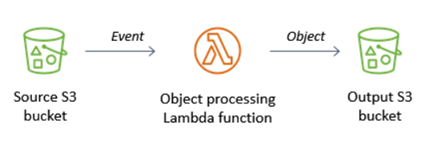
This is the best way where all confusion can be avoided and also makes it easy to maintain the lambda functions in future, there can also be a temporary input bucket and final output bucket, but in case if you have any restrictions on folders and want to manage with only one bucket, then there are alternatives of it, let’s see below.
Using a prefix or suffix in the S3 event notification
When configuring event notifications in the S3 bucket, you can additionally filter by object key, using a prefix or suffix. Using a prefix, you can filter for keys beginning with a string, or belonging to a folder, or both. Only those events matching the prefix or suffix trigger an event notification. So here rather than separate bucket you have to use separate folders in same bucket.
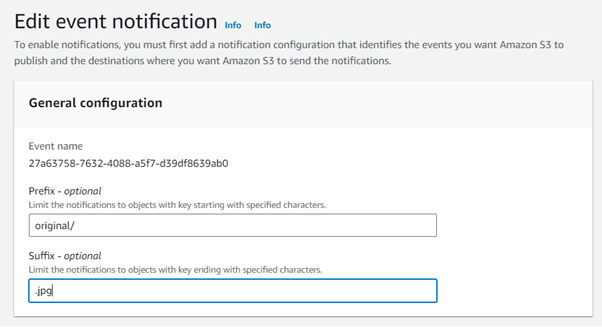
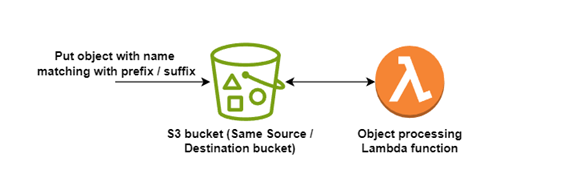
You can then write back to the same bucket providing that the output key does not match the prefix or suffix used in the event notification
Developers with good programming skills always believe in writing code by themselves.
So, this alternate is for them, add condition in lambda function to only process files with specific text in filename and after processing add a suffix to it to distinguish it from non-processed files.
if (!filename.contains(“processed”){
}
filename = filename + “processed”
Monitoring applications for recursive invocation
Whenever you have a Lambda function writing objects back to the same S3 bucket that triggered the event, it’s best practice to limit the scaling.
Use reserved concurrency to limit a function’s scaling, for example. Setting the function’s reserved concurrency to a lower limit prevents the function from scaling concurrently beyond that limit.
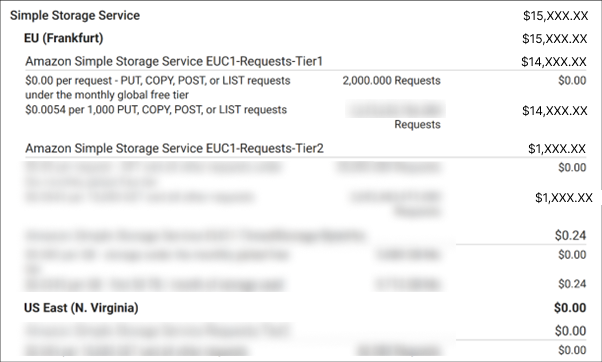
Billing Impact of recursive invocation